Scraping meta ad library costs $40/month on searchapi.io. Apify charges $225 for ~300k ads per month. If there are scrapers out there that can achieve this so why cant I?
Getting there wasnt easy, I thought I can achieve this with few prompts. It took 3 infrastructure rewrites and the discovery that Facebook doesn’t fight bots with captchas, it fights them with silence.
Here’s everything that didn’t work, and the one stupid thing that did.
Why scrape the FB Ad Library?
The FB Ad Library is a goldmine of semi-structured data. Every active ad is public: creative, copy, run dates, spend estimates. Combine that with engagement metrics or brand spend history and you’ve got something DTC brands and marketers will pay for.
Competitive intelligence like this used to cost real money. Now it sits in a public API that’s just annoying enough to access at scale that most people don’t bother.
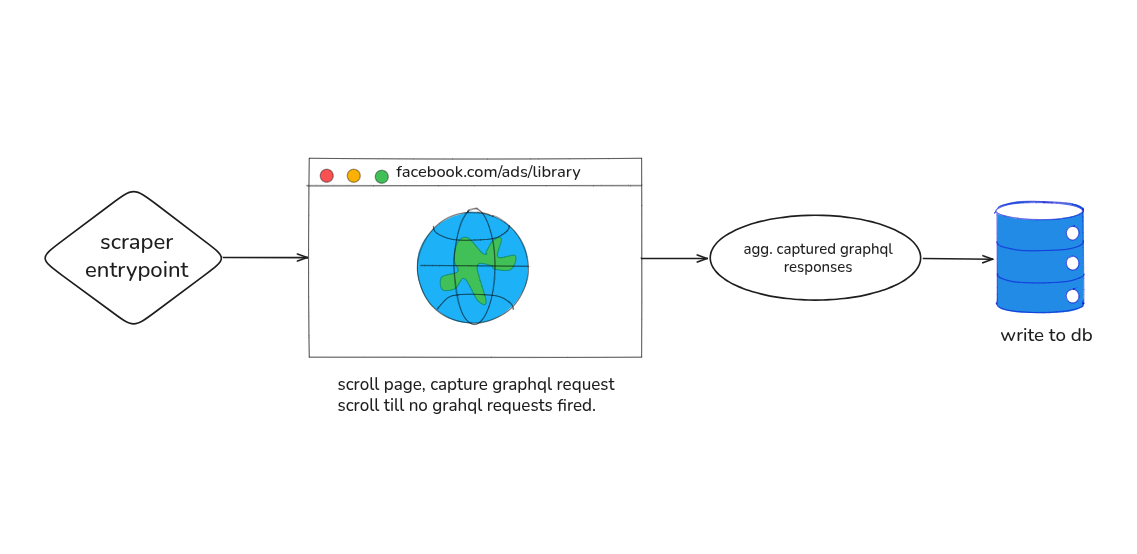
On paper, the plan was simple: launch Puppeteer, open the Ad Library, scroll until nothing new loads, collect the data. Done.
Reality had other plans.
Attempt #1: Cloudflare Workers
I wrote the logic and deployed it on cloudflare workers, the scraper technically ran, but the results were garbage. Missing ads and incomplete payloads. It looked successful until you compared the output against the actual Ad Library.
Attempt #2: AWS Lambda
I ported the worker code to lambda, things looked promising. I started getting real results.
Until I tested multiple pages.
Some returned empty datasets. Others returned ads that didn’t match what I saw manually in the UI.
Then I noticed: my Lambda in the US region worked fine for US-targeted ads, but EU ads went wrong. That was the first real clue. Facebook cared about where the request came from.
You could technically fix this by deploying Lambdas across multiple regions and building a routing layer to pick the right one based on geography. This solution felt not realistic and I couldnt believe that existing scrapers were doing this. There should be a better way.
Lambda + residential proxy
I tried residential proxies. The logic made sense, if Facebook trusts residential IPs more than datacenter IPs, a good proxy should fix everything.
Instead I got empty JSON responses. The behavior got more inconsistent, not less. At this point debugging felt like paranormal investigation. Why does the same code works locally with proxies but doesnt on lambda?????? wth. This was the lowest point for me for this task. (this here could have been solved after attempt 3 learnings but I stuck with attempt 3))
Attempt #3: VPS + residential proxy
I moved everything to a VPS. The Lambda code worked perfectly on my local machine, so I was convinced the right proxy setup would solve it. I converted the logic into a standalone Node.js script, deployed it, attached the proxy, and hit run.
Nothing. No data. Same result as Lambda + proxy attempt.
The exact same proxy worked fine on my local machine. Same IP. Same code. Different outcome.
That’s when things got weird.
The real problem wasn’t the proxy
After way too many hours debugging, I started suspecting the browser fingerprint.
My local machine had a normal Chrome install with years of accumulated “human-ness” baked in: a real browser profile, real fonts, a real graphics stack, actual browsing history. The VPS had a freshly downloaded Chromium binary that basically announced itself the moment it connected.
My first instinct was to add advanced human emulation. Mouse movements, random clicks, typing delays, scroll physics. Probably emotional damage next.
Turns out none of that was necessary.
The actual fix
After all of that. the proxy experiments, the fingerprint rabbit hole, I finally figured out what was actually happening.
Facebook sometimes just refuses to load data when it suspects automation. No errors, no warnings. The page renders perfectly. Looks completely normal. But the underlying API request is never called.
That’s it. That was the whole thing.
I sat there staring at the screen for a moment. Weeks of debugging, three infrastructure rewrites, a growing collection of proxy subscriptions, and the answer was: the page didn’t load the data, so… reload the page.
Detect when the page came up empty. Reload. Retry until valid payloads came through. Done.
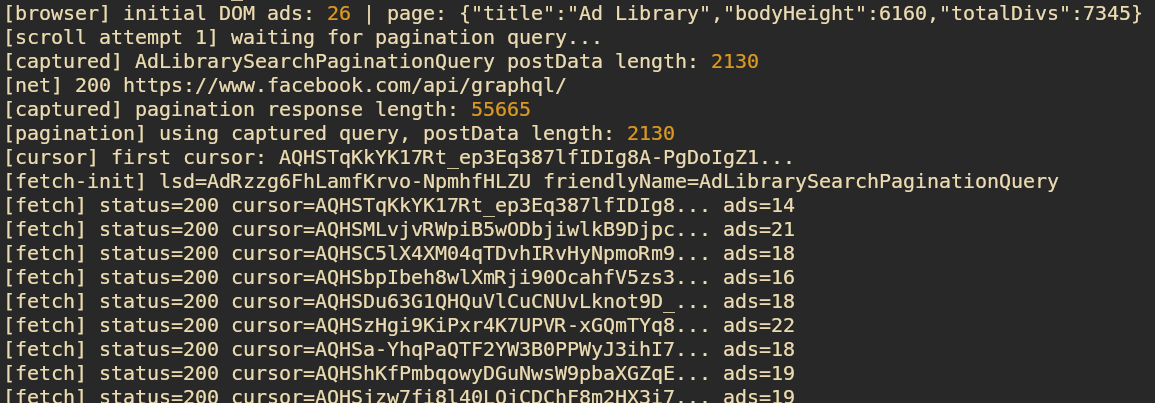
Once the data loaded correctly, I captured the authenticated session and hit the internal paginated API directly instead of scrolling the UI and wasting bandwidth of the proxy (btw I managed to do scrape ~300k ads under 1GB per month with $3 proxy).
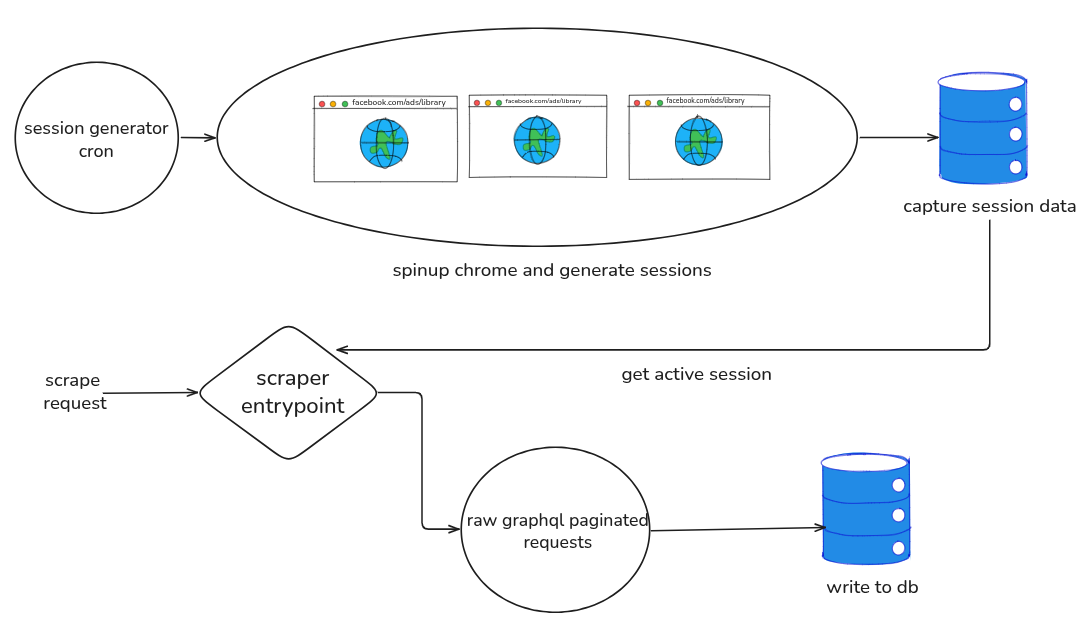
I could pull structured data straight from the network layer. Scraping got faster, results got consistent, and pages with 9,000 ads stopped being a problem. The whole thing felt almost too simple after everything it took to get there.
The funny part is that the breakthrough wasn’t some advanced anti-bot technique. It was realizing: if the page loads empty, just reload it. same could be achieved in cloudflare worker or lambda. I just didnt realize I had to reload the page
The same service costs $40/month on searchapi.io. Apify charges $0.75 per 1,000 ads, which gets painful at scale. I do it with a $3 proxy, which is why our pricing is so much lower than the alternatives .
This is technically a business secret, but honestly it’s cool to share. If you want help with scraping, hit me up on X or at [email protected] .