We needed a data warehouse we actually controlled. Not a managed SaaS, something we could wire up ourselves: operational data from Postgres, event streams from Kafka, analytical queries that had to be fast. ClickHouse was the answer. Here’s what I actually ran into building it.
Postgres to ClickHouse via ClickPipes CDC
The requirement was simple: don’t let ClickHouse go stale. The application was still writing to Postgres constantly, so a one-time dump was useless. We needed everything to stay in sync as it changed.
ClickPipes solved this. It’s ClickHouse Cloud’s managed ingestion layer. The CDC connector hooks into Postgres’s logical replication slot and streams every insert, update, and delete across as it happens. Point it at the source database, pick the tables, data starts flowing. The setup took about an hour.
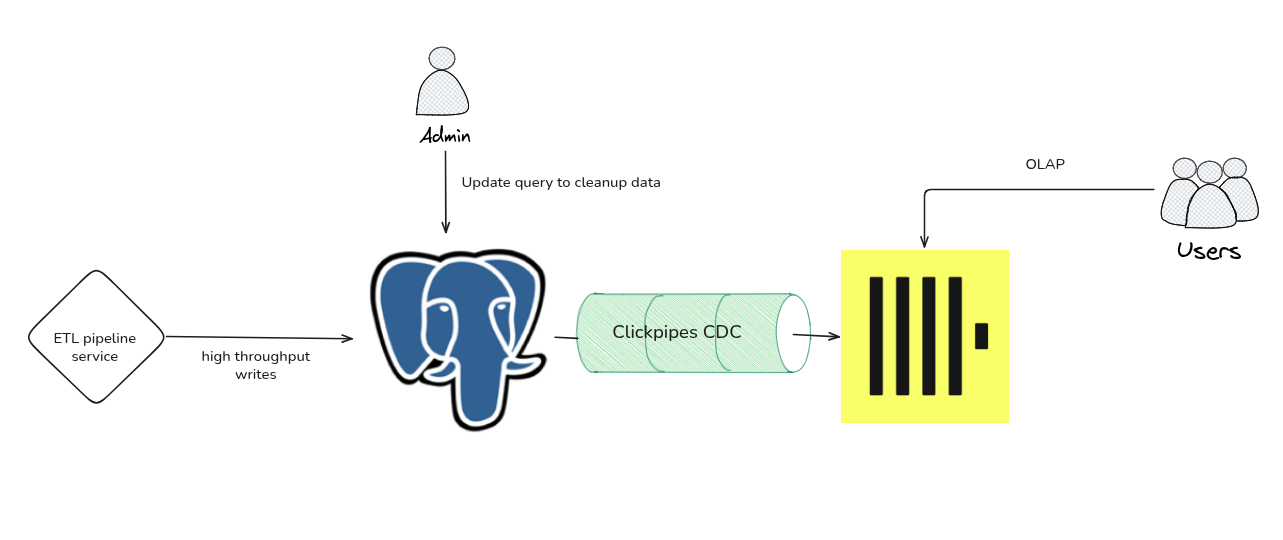
What I didn’t fully get until it bit us: ClickHouse doesn’t do in-place updates. It’s append-only. When a row changes in Postgres, ClickHouse writes a new version of that row rather than overwriting the old one. ClickPipes handles this by mapping your Postgres tables to ReplacingMergeTree, which collapses those duplicate rows down to the latest version during background merges.
ClickPipes configures all of that automatically. But you have to understand it or your queries will lie to you. The merge is eventual. We had a dashboard returning stale values during a high-write window before we figured out why. Once you know, you can write around it. But it’ll catch you once first.
Kafka engine tables
At a previous company, we had four products generating around a thousand events per second from client applications. Thousands of clients, millions of events a day, all landing in Kafka as raw JSON blobs. The goal was product analytics: figure out how people were actually using the software.
The obvious move was a consumer service: read from Kafka, parse and flatten the JSON, write to ClickHouse. We skipped that entirely.
ClickHouse has a native Kafka engine. You create a table that points at a Kafka topic, define the columns you want, and wire up a materialized view that reads from that table and inserts into a real MergeTree table as messages arrive. ClickHouse manages the consumer group, tracks offsets, batches reads. The JSON flattening happened inside the materialized view using ClickHouse’s JSON extraction functions. No consumer process to deploy or babysit. Just a table definition and a view.
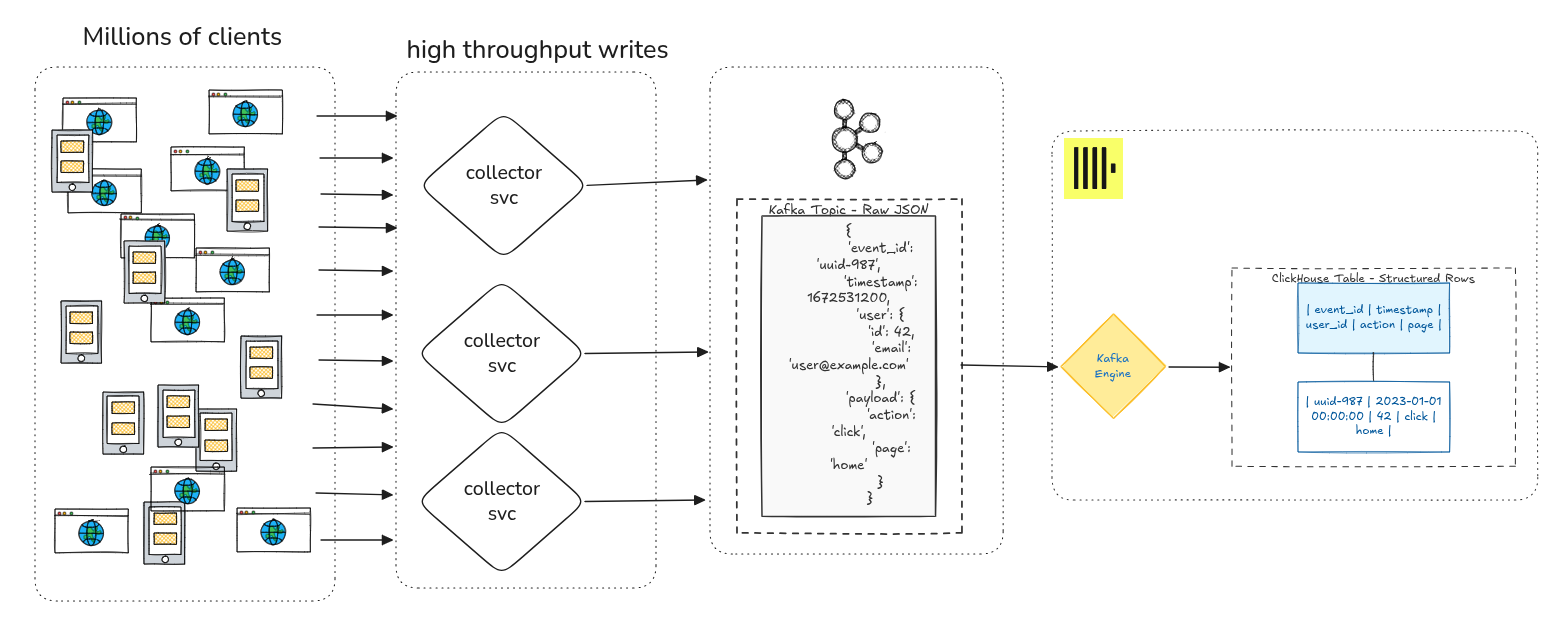
The thing that tripped me up initially: the Kafka engine table isn’t storage, it’s a cursor. SELECT from it directly and ClickHouse commits the consumer group offset. Those messages won’t come back through that table unless you manually reset the offset in Kafka or point the table at a new consumer group. The data still exists in Kafka until retention expires, but as far as that table is concerned, it has moved on. The data you actually query lives in the MergeTree table the materialized view populates. Once that clicks the whole setup makes sense, but before it does you’ll waste an afternoon wondering where your messages went.
A thousand requests per second going into Kafka and landing cleanly in ClickHouse, structured and queryable, without a single line of application code between them. That’s when I started taking ClickHouse seriously.
Fighting ReplacingMergeTree at scale
This is where things got hard.
ReplacingMergeTree deduplicates rows by sort key and keeps the latest version. It does this through background merges: ClickHouse combines data parts over time and collapses duplicates as it goes. At low write rates this works fine. At high write rates, parts accumulate faster than merges can run, and queries start returning duplicates you thought were gone.
The fix everyone reaches for first is SELECT ... FINAL. It forces ClickHouse to apply deduplication at read time rather than waiting for a merge. We tried it. Correct results, no duplicates. At low volume it was fast enough. At production write rates, a query that ran in 50ms without FINAL took 4 seconds with it. With hundreds of unmerged parts, ClickHouse reconciles all of them on every query. We didn’t catch this in staging.
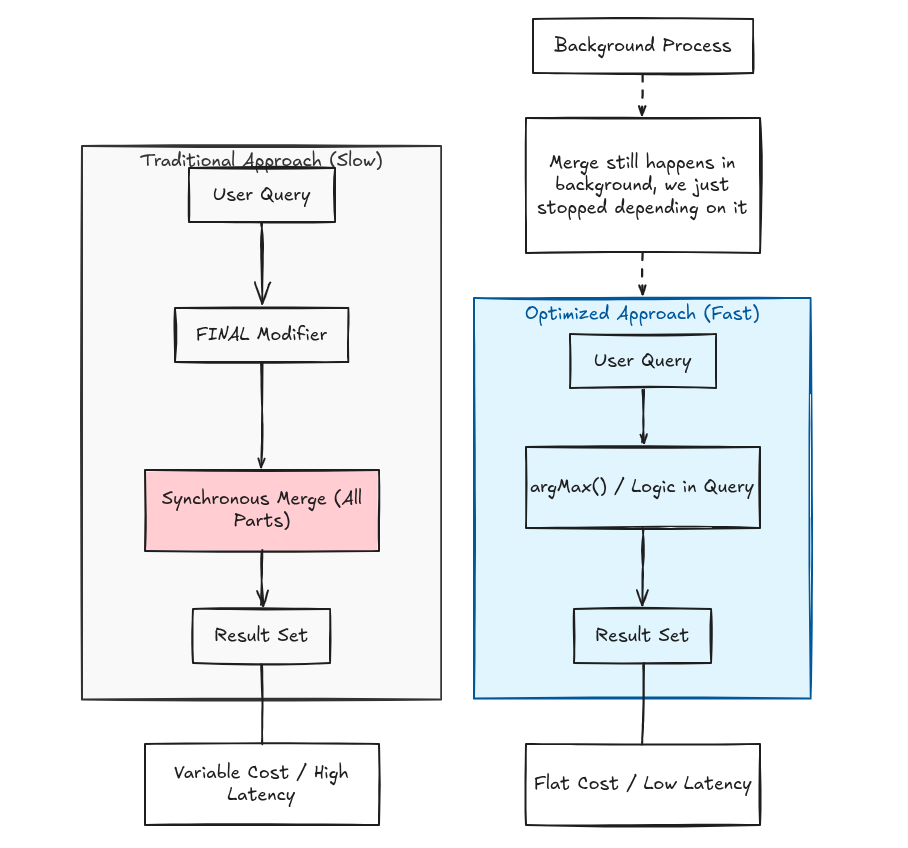
What actually worked: stop depending on the merge for correctness and encode it in the query instead. argMax() picks the value at the highest version column; group by your deduplication key and you get the latest state of every row without FINAL. The query cost stays flat no matter how many unmerged parts exist. More verbose, but the performance is predictable.
Coming from Postgres you expect the storage layer to handle consistency for you. In ClickHouse at scale you end up handling some of that in the query. That was the shift that took me the longest to accept, but once I did the engine stopped feeling like it was fighting me.
CDC and Kafka were things you set up and forget. The ReplacingMergeTree problem changed how I thought about writes and reads more broadly. Postgres hides that complexity behind the storage engine. ClickHouse hands it back and expects you to deal with it.